
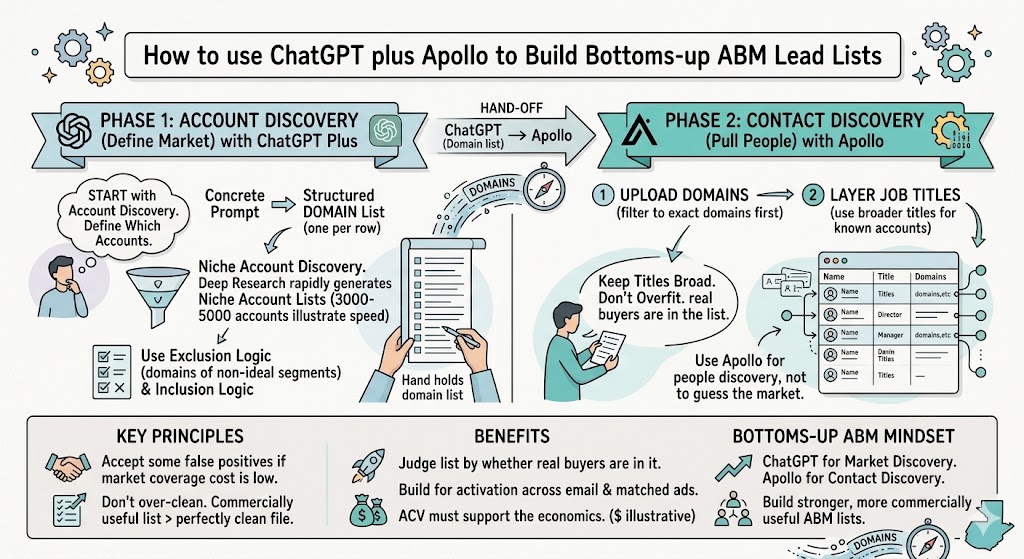
How to use ChatGPT plus Apollo to Build Bottoms-up ABM Lead Lists
A guide to using ChatGPT for account discovery and Apollo for contact discovery when top-down filters are not enough. This post shows how to build bottoms-up ABM lists for niche markets by generating domain lists first, then pulling the right people from the right accounts.

Most founders build ABM lists from the top down because that is what the tools make easy.
You open Apollo, pick an industry, add job titles, layer on geography and company size, and export what comes back. That works well in a lot of markets, and I use it all the time. But there are plenty of cases where top-down filters are not the best path, especially when your market is niche, your buyers have inconsistent job titles, or the built-in industry categories do not map cleanly to how your market actually works.
That is where ChatGPT becomes really useful. As I mentioned in the meeting, “So instead of doing top down, which is what Apollo will do, you wanna do bottoms up.” The idea is simple. Use ChatGPT to build the account list first, usually as a domain list, and then use Apollo to pull the right people from those specific accounts.
This is one of the most practical AI workflows in B2B right now because it solves a very real problem. In a lot of markets, you do not actually need better copy first. You need better market definition. If you can get the right set of domains into Apollo, you can build a much more accurate ABM list than you would get by relying on broad industry filters alone.
Start with account discovery, not contact discovery
The key shift in a bottoms-up workflow is that you stop asking Apollo to tell you what the market is. Instead, you use ChatGPT to define the market at the account level, and then you use Apollo to find the people inside that market. That is a much better approach when the category is unusual or when job titles vary too much from company to company.
In one example from the session, we were working through how to find the right contacts at research universities. The real need was not “find people in a clean industry category.” The real need was to first identify the right institutions. As I said during the call, “You use Manus or ChatGPT or Claude to get a list of the domain names from what you want, and then you only get the people that have, you know, email from those institutions.” That is the workflow. ChatGPT builds the domain list. Apollo turns that domain list into a people list.
This is also why I tell founders to think like a computer when they prompt ChatGPT. Vague descriptions are not enough. You have to translate the market into something the model can actually return as a structured list. In that university example, the useful prompt was not a fuzzy description of “schools that care about research visibility.” The useful prompt became a concrete request for the top 200 research universities and their domains. Once you have that, the rest gets much easier.
- Use ChatGPT first when the market is niche or hard to define through standard filters.
- Ask for domains, not just company names, because domains are what Apollo can work with cleanly.
- Turn fuzzy market descriptions into specific, computable requests.
- Treat account selection as the first layer and contact selection as the second layer.
That is the big mental model. Bottoms-up ABM starts with accounts. Contacts come second. When founders reverse that order, they usually get a cleaner and more commercially useful list.

Use ChatGPT Plus to build the domain list you actually need
What makes ChatGPT Plus useful here is not that it replaces your prospecting tools. It does not. What it does is help you rapidly generate niche account lists that would be slow or annoying to build manually.
As I explained in the session, “You can, as we showed today, use ChatGPT’s deep research,” and with that workflow, “you can build niche account lists.” I also pointed out that we demonstrated how to “build a short list of, like, two hundred accounts within thirty seconds,” and that you could use deep research to build lists of “three thousand, five thousand accounts.” That is a big deal when you are entering a vertical where no single lead database has a clean out-of-the-box category for what you need.
This also works well for exclusion logic, which is something a lot of teams overlook. In another example, I described using ChatGPT to generate a list of hotel domains I did not want, then putting those into Apollo as exclusions so the remaining results were, by definition, the right segment. The client wanted three-star hotels and below, not four-star and five-star chains. On the surface that sounds messy. In practice, it became very manageable because AI made the exclusion list easy to create.
That is one of the underrated strengths of this workflow. ChatGPT is not just useful for inclusion lists. It is also useful for building exclusion lists, competitor lists, public institution lists, conference attendee list cleanup, trade association member lists, and other account sets that help you sculpt the market before you ever get into contact-level data.
- Ask ChatGPT for one domain per row so the output is easy to use.
- Build inclusion lists when you know exactly which accounts belong.
- Build exclusion lists when it is easier to define what you do not want.
- Use Deep Research when the account set is large or the market is hard to map manually.
Once you have the domains, you have what you need. That is the handoff point. ChatGPT gives you the account universe. Apollo gives you the people inside it.
Bring the domains into Apollo and let Apollo do what it does best
Once the domain list is ready, Apollo becomes the execution layer. This is where you stop using broad industry filters and start restricting the search to only the companies you care about. Then you layer job titles on top.
In the university example, after bringing those domains into Apollo, the search surfaced about 1.4 million people who worked at the top 200 universities. From there, the next move was to narrow by role. That is where bottoms-up gets powerful. Instead of hoping Apollo’s industry tags knew what the market was, we told Apollo exactly which institutions mattered and then asked it to find the relevant people inside them.
This is also where founders need to resist the urge to get too fancy with job titles. In that same exercise, the instinct was to search only for very specific titles like digital archivist or digital collections archivist. As I said on the call, “I think you’re getting too specific here.” That was not just a throwaway comment. It is a core ABM lesson. If you narrow too hard on title strings, you often lose real buyers who have idiosyncratic or institution-specific titles.

The better move is usually to start broader, especially if the account universe is already tightly defined. In that example, once we broadened from specialty titles to librarians more generally, the reachable audience got much more useful. At that point, the question was no longer whether every single person in the list was perfect. The question was whether the real buyers were in the list. That is the standard that matters.
- Upload or filter to the exact domains first, then layer job titles second.
- Keep titles broader when the account list is already highly specific.
- Use Apollo to find people within known-good accounts, not to guess the market from scratch.
- Export all fields you may need later since there is no reason to make the file smaller than necessary.
That is why I like the combination. ChatGPT handles market discovery. Apollo handles contact discovery. When you let each tool do the part it is best at, the workflow becomes much more reliable.
Go broader than feels comfortable, then refine with evidence
One of the biggest mistakes I see with bottoms-up ABM is over-cleaning the list too early. Founders want the file to look perfect. They want every title to be precise and every contact to look obviously relevant. In practice, that can be a very expensive instinct because it causes you to remove people who really do influence the buying decision.

That is why I made this point clearly in the session: “Go a little bit wider with your targeting because the cost of showing ads is low.” In the university example, the audience of librarians across those institutions was about 6,400 people, and I walked through the math that you could show ads to all 6,400 for around $180. If the account set is good and the economics work, it is often completely rational to tolerate some false positives in order to make sure the true positives are not excluded.
This matters even more if you are building matched audiences, not just outbound lists. In another part of the training, I explained that one client’s ABM list building process produced 254,000 people in the target market, and we expected about half of those to match into ad platforms, giving us an audience of around 120,000. That is the game. You are not just building a cute CSV. You are building a marketable audience that can be activated across email, ads, retargeting, and follow-up.
There is also a practical economic threshold here. As I mentioned in the training, this kind of ABM motion generally starts making sense when ACV is at least about $1,000 a year, and it gets much easier when it is a few thousand dollars and up. If your ACV is too low, the data costs, ad costs, and outbound effort can get out of proportion. If the ACV is there, the list becomes a real asset.
- Do not judge the list only by cleanliness. Judge it by whether the real buyers are in it.
- Accept some false positives when the cost of market coverage is low.
- Build for activation across ads and outbound, not just for contact storage.
- Make sure the ACV supports the economics of data, ads, and outreach.
The founder takeaway is straightforward. ChatGPT plus Apollo is not a clever hack. It is a practical way to build better ABM lists when top-down filters are too blunt for the market you want to reach. As I said near the end of the session, “The way to breakthroughs is mistakes. The way to innovation is screw ups.” So the right move is to spend a few hours playing with this workflow, build some account lists, push them into Apollo, and let the market show you where the next version needs to improve.